
著者:アスタミューゼ株式会社 エグゼクティブチーフサイエンティスト 川口伸明(薬学博士)
1. はじめに
近年、AI(人工知能)が驚異的な進化をとげています。「ChatGPT」や「STABLE DIFFUSION」に代表される生成AIは、自然言語(日常的な文章や対話)でプロンプト(prompt:呪文)を入力するだけで、翻訳や文章要約などのtext-to-text変換はもとより、画像や音声、動画・アニメや歌唱入りの音楽、小説やドラマの台本、さらにはプログラミングなど多様なアウトプットをすばやく半自動で生成する魔法のような技術です。これにより、ビジネスやイノベーション、クリエイティブなどの分野に革新をもたらしています。
AIの進化により、文字だけでなく音声や画像、動画など、さまざまな感覚入力が可能となりました。これを「マルチモーダルAI」と呼ぶこともあります。例えば、GoogleのAIチャットボット「Bard (PaLM2搭載) 」は、画像認識や文章読み上げ機能を追加してマルチモーダル化しています。
さらに、アップロードした画像について質問できる「MiniGPT-4」や、論文などのPDFを読み込んで質問できる「ChatPDF」、WebページやYouTube動画の要約や全文書き起こしができる「ChatGPT Glarity」や「Glasp」など、さまざまな媒体を処理できるGPTベースのアプリやモジュールが次々と登場しています。
また、「HuggingGPT」は、自然文による簡単な指示だけで複数の機械学習モジュールを組み合わせてタスクを半自律的にこなすアプリです。「AutoGPT」や「BabyAGI」、「GODMODE」など、外部ツールやデータにアクセスしながらタスクを立案、実施するGPTベースのプラットフォームも登場しています。
一方で、生成AIへの過剰な期待や過信に慎重な意見も少なくありません。「記号接地問題」(シンボル・グラウンディング:言葉の意味を理解しているか)や、高度なAI技術の驚異的な到達点(例えば「AI-directed science」)など、その負の側面が抱えるリスクは、あまり知られていない状況です。私たちはまさに、プレ・シンギュラリティとよぶにふさわしい状況を目の当たりにしています。
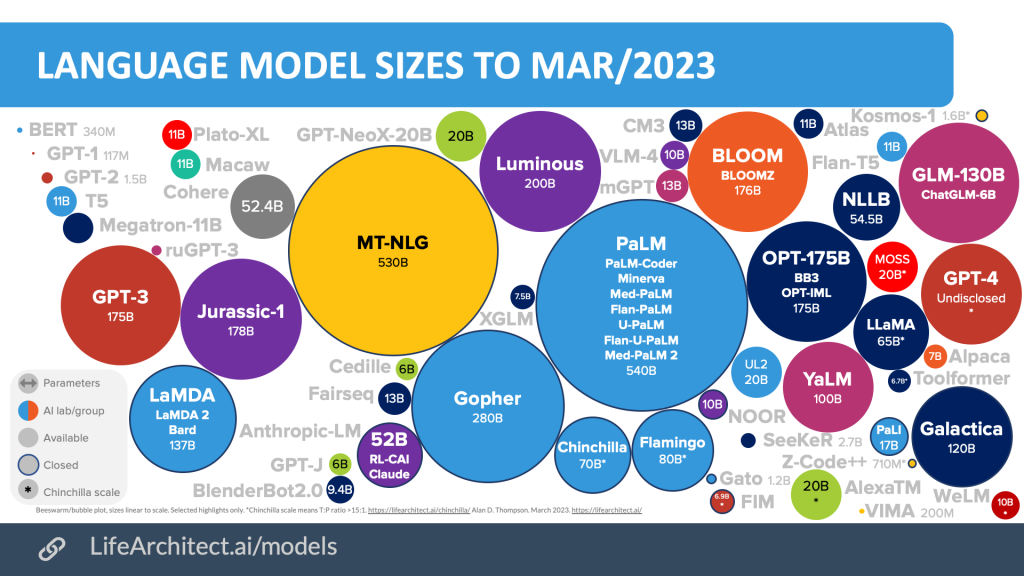
図1と図2は、2022年前後の生成AIの群雄割拠の様子をしめすAlan D. Thompson氏によるマップです。この1年でも、GPT-4の公開をふくめ、さまざまなセクター間でひしめき合うような動きが如実に示されています。この状況を、古生代カンブリア紀(およそ5億4200万年前から5億3000万年前のあいだ)の生物種の急激な増加と多様化を意味する「カンブリア爆発」になぞらえて、「生成AIのカンブリア爆発」と呼ばれることもあります。

こうした生成AIの隆盛は、2017年にGoogleが発表した自然言語処理の深層学習モデルである「トランスフォーマー(transformer)」(注1)の想定外の能力がきっかけでした。自己注意(Self-Attention)機構により、もともとは翻訳などの文章変換の高速高精度化を目指して作られたものでしたが、2018年には「文脈を読める」革新的な自然言語処理モデルである「BERT」を生み出し、その後、Vision Transformer(ViT)やTransGANなど、画像や音声を含めた幅広い処理に応用できるようになりました。これらが今日の生成AIの基盤となっています。
注1:Attention Is All You Need:arXiv.1706.03762 (Jun 12, 2017)

2. 世界の生成AI関連情報解析
今回、弊社保有の「特許」、「グラント(公的研究費)」、「論文」、「ベンチャー企業」のデータベースを活用し、GoogleがTransformerを発表した2017年以降の全世界の生成AI関連の動向を調べました。生成AIの開発だけでなく、応用や生成AI開発のための基盤技術などを含みます。ここでは、とくに最近の特許と論文の動向を中心に紹介します。
2-1. 母集団定義
今回の母集団は、以下の「(要素1)+(要素2)×(要素3)」 の検索式を用いて作成しました。キーワードの統計解析(TFiDF)および抽出リストの目視確認により、ノイズは10%未満と判断しました。
- 要素1:生成AIの定義語: generative ai, pre-trained transformer, chatgpt など
- 要素2:AI定義語: artificial intelligence, deep learning, ConvNet, gans, lstm など
- 要素3:生成AI特徴語: transforming text, transformer model, generator model, text-to-image, prompt engineering, few-shot learning など
2-2. 作成した母集団の概観
4つの異なるデータソースから母集団を構築し、主な指標を図4に示します。
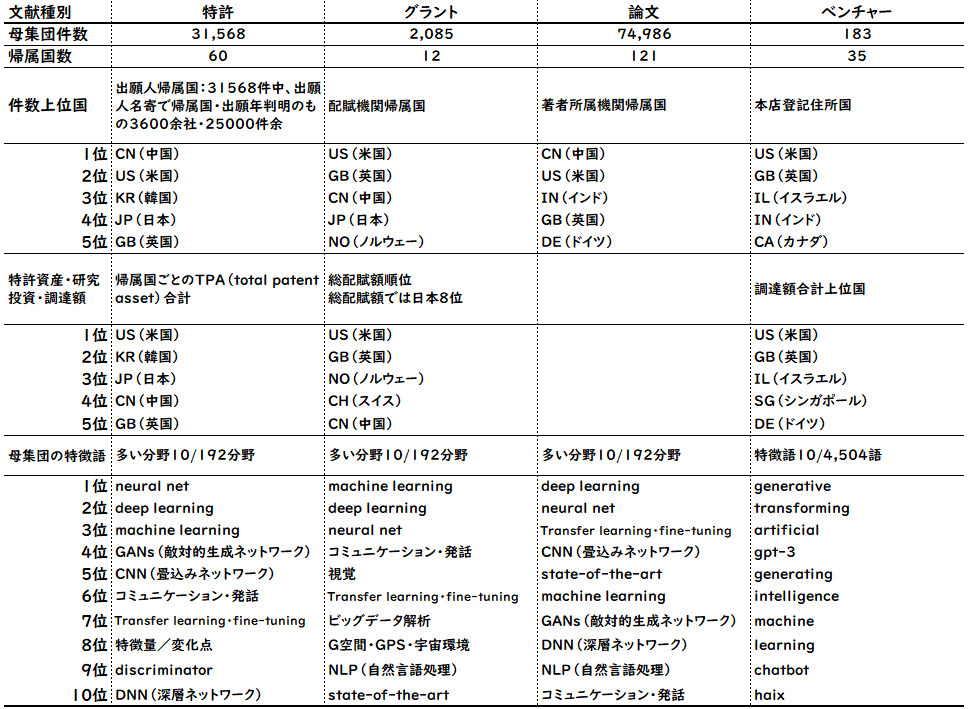
4つのデータソースすべてにおいて、米国または中国が首位。とくに特許出願数では中国(11,975件)が、グラント件数では米国(981件)がそれぞれ2位の2倍近い件数で他国を引き離しています。論文数では米中がほぼ互角(中国11,875件、米国11,174件)で3位のインドを5倍近い件数で圧倒。日本は特許出願数とグラント件数のいずれも4位です。
国ごとの特許資産の総量を表すTPA(total patent asset)合計では、米国が圧倒的な首位で、2位の韓国、3位の日本の7~8倍の値を示しました。件数が首位だった中国は4位になりました。
グラントの総配賦額(各国の基礎研究投資額の指標)では、米国が首位、英国が2位で両国が3位以下を大きく引き離しています。ベンチャー・スタートアップの新規設立数と資金調達額では、米国が圧倒的な首位を獲得しています。
4つのデータソースすべてで出現する母集団特徴語(本領域の特徴的なキーワード)は、おおむね深層学習に関連するものであり、ベンチャー以外の3つのデータソースでも多く見られる研究テーマです。
2-3.世界の特許出願および論文発表動向
(1)主要国の生成AI関連特許出願数(年次推移)
特許母集団31,000件余のうち、出願人名寄せにより、帰属国があきらかになった60カ国3,600社余の特許25,000件余について、年次推移を示したものが図5です。
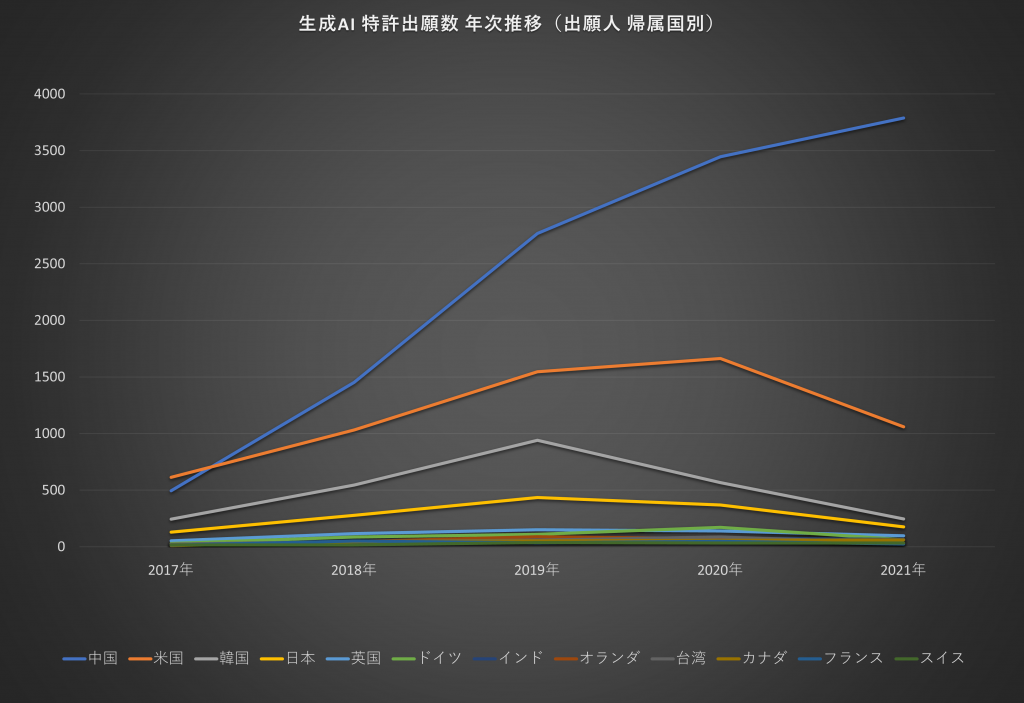
中国からの出願数が圧倒的に多く、それにつぐ米国、韓国、日本を大きく引き離しています。また、米国は2020年、韓国と日本は2019年をピークに、以降は出願件数が減少しています。2022年以降は未公開が多いため、集計していません。
(2)主要国の生成AI関連論文発表数(年次推移)
論文母集団約75,000件について、主著者所属機関の帰属国別の年次推が図6です。
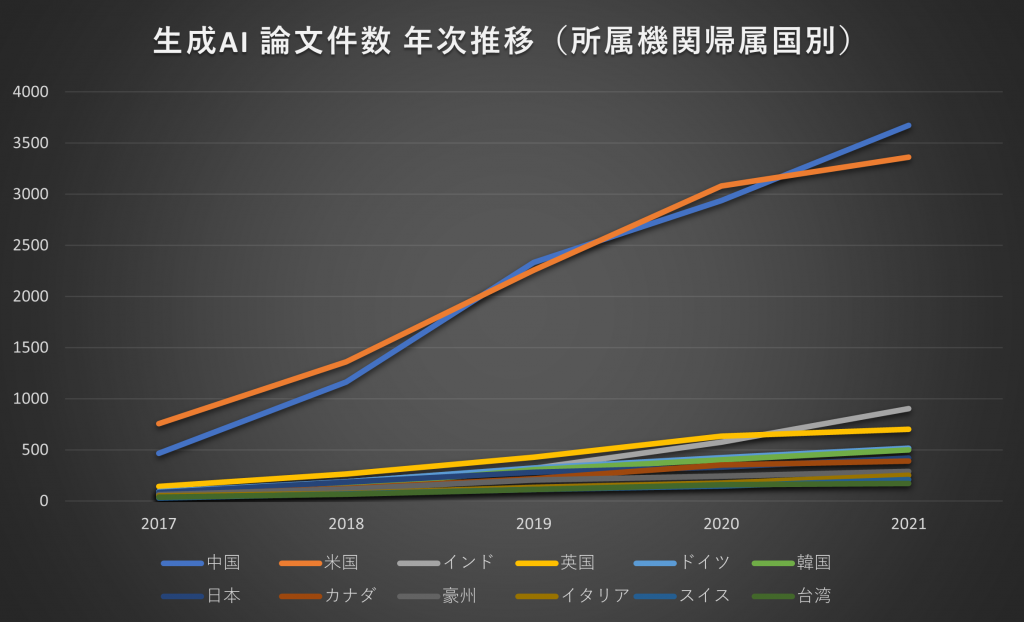
米国(11,174件)と中国(11,875件)がほぼ互角です。2012年以降の直近まで、ほぼ並行した動きとなっています。3位以下のインド、英国、ドイツ、韓国などは論文件数で大きく劣後しています。日本は論文総数で7位(1,367件)となっています。
論文にくらべると、特許出願における米国の降下傾向は矛盾しているように見えます。しかし、中国の特許は国内出願が多く、有効特許の半数以上を国際出願している日・米・欧と単純比較することはできません。
AIに限らず、多くの分野で中国の特許が飛躍的に伸びている背景には、中国政府が2006年に策定した「国家中長期科学技術発展計画(2006-2020年)」(注2)があります。この政策により、中国は研究開発支出の対GDP比率を2020年までに2.5%以上に引き上げることをめざし、自国企業による自主的なイノベーションを推進してきたと考えられています。
注2:中国のイノベーション政策の効果推計-企業データを用いた分析(独立行政法人経済産業研究所)
https://www.rieti.go.jp/jp/publications/nts/14e056.html
(3)GAFAM等注目企業の論文発表
GAFAMを中心に、AI関連の注目企業の論文発表件数の推移をまとめたものが図7です。
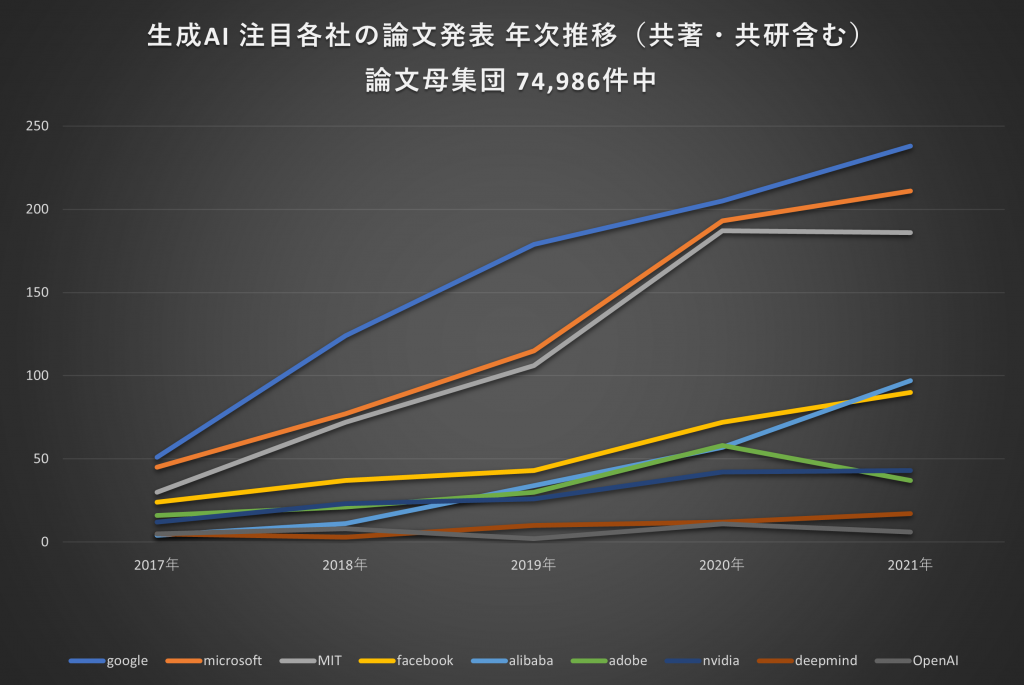
件数を見ると、Googleが818本、Microsoftが662本で、Facebook以下を大きく引き離していることがわかりました。
Googleの論文としては、冒頭でもふれた「トランスフォーマー」の論文「Attention Is All You Need」が圧倒的な引用数(76,000件以上)で有名です。
Microsoftは「Sparks of Artificial General Intelligence」という論文(注3)が要注目です。GPT-4がAGIの事実上の初期バージョンだということが語られています。
注3:Sparks of Artificial General Intelligence: Early experiments with GPT-4:arXiv:2303.12712 (Apr 13, 2023)
OpenAIは「自然言語モデルのサイズと計算予算が増加するにつれてなめらかに性能が向上し、べき乗法と定数スケーリング法則にしたがう」などの「Scaling Laws」に関する論文(注4)を発表しています。OpenAI自体の論文は少ないのですが「GPT-3 or 4」「ChatGPT」に言及する他者による論文は約2,700件におよび、研究者や投資家の関心の高さがうかがえます。
注4:Deep Learning Scaling is Predictable, Empirically:arXiv:1712.00409 (Dec 1, 2017) / Scaling Laws for Neural Language Models:arXiv:2001.08361 (Jan 23, 2020) / Scaling Laws for Autoregressive Generative Modeling:arXiv:2010.14701 (Oct 28, 2020)
2-4.特許の実力比較
上記の出願人による名寄せをした31,000件余の特許母集団に対して、アスタミューゼ独自の手法によるスコアリング(定量評価)を行ないました。母集団に含まれる特許のうち、出願人の名寄せにより、3,600社余の特許と25,000件余の法人(企業・大学・行政・国際機関等)が特定されています。特定されない6,000件ほどは、個人名や帰属不明の団体などになります。
評価指標としては、特許出願件数のほか、アスタミューゼが独自にさだめる指標であるPIS(patent impact score:個々の特許の相対的強さ・影響度)、PES(patent edge score:特定出願人の自社特許中の最高スコア)、TPA(total patent asset:特定出願人の保有特許資産の戦力価値総量)をもちい、それぞれ上位10件をまとめました。なお、10位までにふくまれなくとも、日本企業の各指標トップ1社、AIに関連性の強いGAFAMの5社とIBM、DeepMindは表にいれました。
また、OpenAIの特許は現在までのところ、公開されていないようです。
評価指標としてもちいたスコアの定義や活用法についての詳細は以下をご参照ください。
アスタミューゼの未来予測手法~『2060 未来創造の白地図』の舞台裏~(前編)
https://note.com/astamuse/n/n2788bc17b07c
(1)特許件数上位企業
図8は特許件数のランキングです。
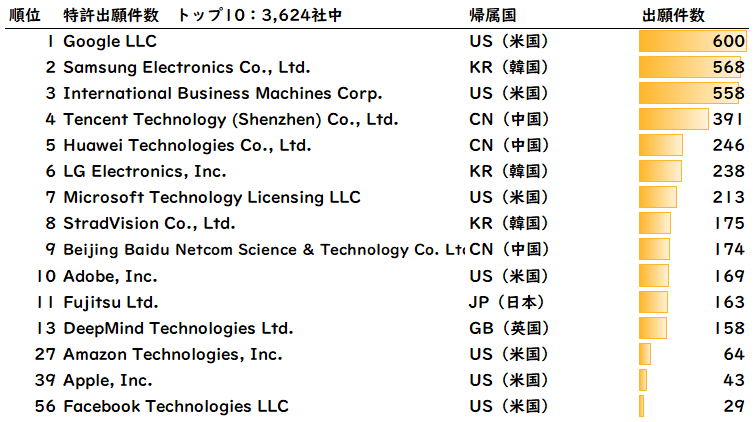
特許件数の1位から3位は、Google、Samsung、IBMとなり、上位10位までは米国・中国・韓国の有名企業が占めています。11位には富士通が入りました。富士通の最高スコア特許は、「予測分析のための時系列データセット生成方法および装置」(US10185893B2、PIS:89.34)となります。
(2)PES(特許最高スコア)上位企業
図9はPES(特許最高スコア)のランキングです。
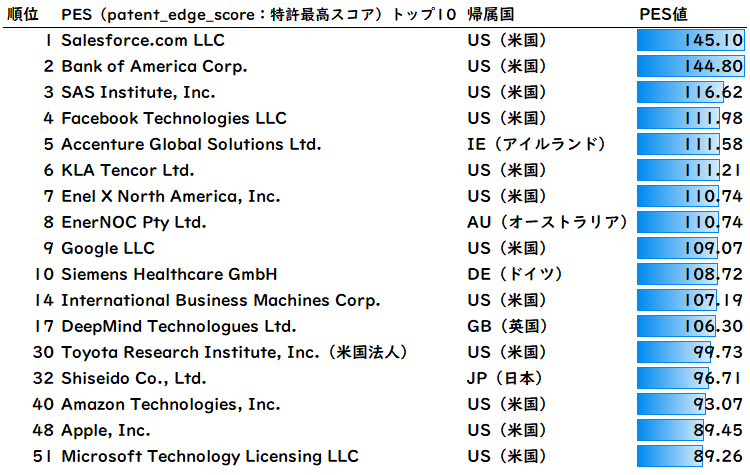
PES(最高スコア)ではSalesforce、Bank of America、SASといったビッグデータをあつかうサービス企業や金融機関が上位を占め、4位にFacebook、9位にGoogleがランクインしています。17位にはDeepMindも入っています。日本企業ですと、30位にトヨタの米国法人Toyota Research Institute、32位には資生堂が入っています。
PESは各社のパテントインパクトスコアが最高得点の特許の価値を示すもので、PESが大きい企業は、技術力の高い大企業が多い特徴があります。高スコア特許を多く保有する企業は競争力が高いといえます。
Salesforceの最高スコア特許は「ロールバック機構を備えた機械学習モデルのトレーニングおよび展開を実施するためのシステム、方法、および装置」(US10713594B2)で、母集団内における全企業の特許では最高得点である、スコア145.10をマークしました。
Bank of Americaの最高スコア特許は「動的インターフェース機能を提供する機械学習エンジンを備えたデータ処理システム」(US10788951B2、PIS:144.80)、SASは「機械学習アルゴリズムの検証セット」(US10754764B2、PIS:116.62)です。
Toyota Research Instituteの最高スコア特許は「特権情報を用いたシミュレーションのフォトリアリスティックな後処理の敵対的学習」(US10643320B2、PIS:99.73)、資生堂は「仮想顔メイクアップ除去およびシミュレーション、高速顔検出およびランドマーク追跡、入力ビデオの遅延および揺れの低減、ならびにメイクアップ推奨方法のためのシステムおよび方法」(US10939742B2、PIS:96.71)です。
(3)TPA(総合特許資産)上位企業
TPA(総合特許資産)は、平均以上の強みを持つ特許のスコアと当該特許の権利残存年数の積を総和したものです。これは、その企業の持つ競争力ある特許の保有戦力(競合圧倒力×持続時間)と見ることができます。蓄えられた力ですのでAsset(資産)という表現を使っています。私たちは、このTPAを企業の競争力比較でもっとも重要視していますが、あわせてPESや件数も重要な指標として見ています。
図10はTPA(総合特許資産)のランキングです。

TPA1位から3位にはIBM、Google、Adobeが入り、7位から9位はMicrosoft、DeepMind、Amazonとなりました。まさに、AIの覇者と強豪たちの集団といったおもむきです。
1位のIBMは件数でも3位に入っており、その最高スコア特許は、自然言語の質問に答えることができる方法に関する「時間の経過に伴う概念の分析」(US11379548B2、PIS:107.19)となります。
2位のGoogleは、件数で1位、PSEで9位と、3つのランキングすべてで10位以内に入っています。生成AIにおいて、その技術力の高さはうたがう余地がありません。
13位に入ったNECの最高スコア特許は「リソース割り当てと異常検知のための機械学習ベースのリソース予測方法とシステム」(US10579494B2、PIS:94.83)です。
韓国の企業ではSamsungが強い印象がありますが、TPAランキングにおいてはSamsungが6位、StradVisionが5位で要注目です。13位にはLGも入っています。StradVisionは自動運転におけるAI物体認識アプリやADAS(先進運転支援システム)を提供しており、最高スコア特許は「追跡ネットワークを含む畳み込みニューラルネットワークを用いた物体追跡方法およびそれを用いたコンピューティングデバイス」(US10269125B1、PIS:76.39)です。Samsungの最高スコア特許は「カスケードネットワークトレーニング、カスケードネットワークトリミング、および拡張畳み込みによる効率的な超解像深層畳み込みニューラルネットワークを設計するためのシステムおよび方法」(US11354577B2、PIS:91.45)になります。
(4)帰属国ごとの特許競争力比較
図11は帰属国ごとのTPAのランキングです。
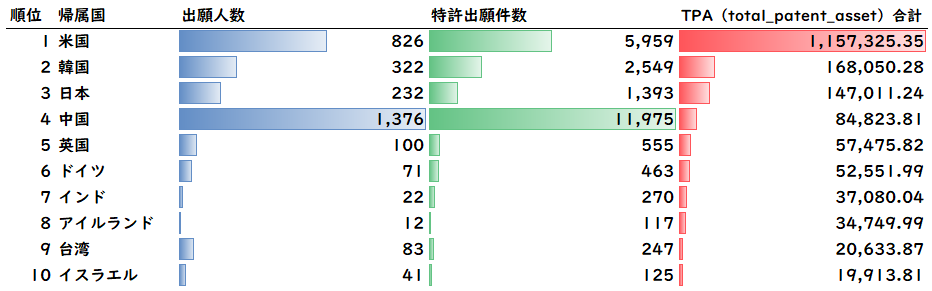
米国が圧倒的に優勢で、2位が韓国、日本は3位、中国は4位です。日韓の差は大きくありませんが、米国には大きく差をつけられています。
2-5.各社の興味深い特許紹介
上記ランキングに出ていないものもふくめた、GAFAMやとくに興味深いテーマの特許を紹介します。ここで紹介する特許はあくまでも一例であり、当該各社の最近の研究開発を網羅したものではありません。また、各特許に付されたPIS(patent impact score)は後願特許に対する相対的な影響度の現時点での指標であり、技術そのものの成長性や経済的価値を代表するものではないことにご注意ください。
- Google LLC(米国)
- US10134393B2「音響シーケンスの表現を生成する」(出願日:2017/7/31、PIS:108.02)
- 音声シーケンス(時間的に分割して得られる音声特徴量の並び)から音素表現(発話の最小単位の並び)を生成するためのニューラルネットワークの方法、システム、および装置に関する。
- Amazon Technologies, Inc.(米国)
- US10554817B1「コンタクトセンターシステムにおけるコンタクトワークフローと自動サービスエージェントの自動化」(出願日:2018/12/12、93.07)
- コンタクトセンターシステムで、サービスエージェントと顧客の行動パターンを検出し、自動化されたワークフローと自動化されたサービスエージェントを生成するシステムに関する。
- Facebook Technologies LLC(米国)
- US10823960B1「機械学習を用いた音声出力のパーソナライズイコライゼーション」(出願日:2019/9/4、PIS:60.65)
- ユーザーの耳の特徴を機械学習モデルに入力し、ユーザーに最適な音声出力を生成する方法。
- Apple, Inc.(米国)
- US10936908B1「画像を用いた点群のセマンティックラベリング」(出願日:2020/5/7、PIS:89.45)
- 3次元の空間内のオブジェクトを反映した点群データと画像を組み合わせることで、オブジェクトの位置を推定し、2次元の畳み込みニューラルネットワークを用いてオブジェクトに対する予測を行い、最終的な意味ラベル付けされた点群を生成する方法。
- Microsoft Technology Licensing LLC(米国)
- US10878195B2「任意の文書からの非構造化表や意味情報の自動抽出」(出願日:2018/5/3、PIS:89.26)
- 任意の文書から非構造化テーブルと意味情報を自動的に抽出する方法、システムおよび装置。
- DeepMind Technologies Ltd.(英国)
- US11354548B1「リカレントアテンションを用いた画像処理」(出願日:2020/7/13、PIS:105.11)
- 画像の全体を処理するのではなく、各画像から一部の領域を抽出して処理することで、効果的に様々な画像処理タスクを実行することができる再帰的アテンションに関する。
- Anthropics Technology Ltd.(英国)
- US2022012846A1「デジタル画像修正法」(出願日:2019/11/14、PIS:43.97)
- 画像の一部分や全体の特徴(色や形や明るさなど視覚的要素)を変化させるためのニューラルネットワークの方法、システム、および装置。
- NVIDIA Corp.(米国)
- US2019297326A1「空間的にずれた畳み込みを用いたビデオ予測」(出願日:2019/3/21、PIS:85.10)
- 過去のビデオフレームと光学フローに基づいて高解像度のビデオフレームを生成するための深層学習ニューラルネットワークを実装する方法、装置、システムに関する。
- Adobe, Inc.(米国)
- US10719742B2「生成的敵対的ニューラルネットワークを利用した画像コンポジット」(出願日:2018/2/15、PIS:96.31)
- 前景オブジェクトを背景画像の幾何学的視点に自動的に整列させる正しい幾何学的アラインメントを提供する画像合成に関する。
- Disney Enterprises, Inc.(米国)
- US11017599B2「仮想空間の利用者に物語体験を提供するためのシステムおよび方法」(出願日:2019/10/29、PIS:86.85)
- 仮想空間内でAIキャラクターが興味深い場所を巡る経路を生成するために、機械学習に基づく技術を使用、システムは独自の経路を生成してユーザーに物語性のある体験を提供。また、ユーザーの選択に応じてAIキャラクターの行動や経路を自動的に生成することも可能。
3.まとめ
2023年6月28日に発表された「The Global AI Index :4th iteration of the Global AI Index」には、各国のAIへの投資、イノベーション、実装の3つの要素に基づいて62カ国のランキングが公開されています。米、中、シンガポール、英、カナダ、韓国などに続き、日本のランクは12位です。日本はResearchやCommercialは強いのに、DevelopmentやTalent(人材)、Infrastructure、Operating Environmentが弱いという評価です。
今回紹介した特許の強み(TPA)分析からも、今回紹介できなかったグラント(科研費など公的研究費)分析からも、日本の研究力と技術力の高さは見えます。しかし、日本発の生成AIのプラットフォームが世界で認知されるという状況にはありません。
その一方で、データやアルゴリズム系ではない事業分野の日本企業の中にも、高いTPAやPIS(特許スコア)を持つ例も散見されるなど、具体的な事業に生成AIを取り込み、活用していくことにかけては期待がもてます。
2023年4月、OpenAIのCEOであるSam Altman氏が岸田首相と会談し、言語モデルで日本語をより強化していく話が出ました。著作権法の関係でAIの学習において拠点を日本に持つことが有益という意見もあります。今後、MADE-IN-JAPANならぬ、PreTRAINED-IN-JAPANがハイスペックAIのブランディングにつながる可能性もあるでしょう。
生成AIの多様な応用研究とそれを実装したビジネスの展開は、日本のイノベーションや新しい産業のコアを担う可能性があり、そのためにも、国内での人材育成や弾力的な教育投資が喫緊の課題と言えます。この点、中国は特許出願件数が多く、人材育成も非常に進んでいると考えられます。経済安全保障の観点からも注視していく必要があります。
AI-directed scienceなどより高度のAIアーキテクチャや、脳科学との連携によるAGI(汎用人工知能)の構築などにも日本の役割は大きいと思います。今回取り上げられなかったAIに関するより深い議論は、拙著『2060未来創造の白地図』の続編、2023年12月に出版予定の新著(タイトル未定、技術評論社)にくわしく書かれる予定ですので、ご期待ください。
著者:アスタミューゼ株式会社 エグゼクティブチーフサイエンティスト 川口伸明(薬学博士)
【関連記事】
本稿の元データを利用した記事「Google一転、検索に生成AI導入 Microsoftを追う 攻防 生成AI(上)」が、日本経済新聞 2023年7月3日電子版および4日紙面テック面トップに掲載されています。
さらに詳しい分析は……
アスタミューゼは世界193ヵ国、39言語、7億件を超える世界最大級の無形資産可視化データベースを構築しています。同データベースでは、技術を中心とした無形資産や社会課題/ニーズを探索でき、それらデータを活用して136の「成長領域」とSDGsに対応した人類が解決すべき105の「社会課題」を定義。
それらを用いて、事業会社や投資家、公共機関等に対して、データ提供およびデータを活用したコンサルティング、技術調査・分析等のサービス提供を行っています。
本件に関するお問い合わせはこちらからお願いいたします。
https://www.astamuse.co.jp/contact/






